Filter secrets from Kubernetes logs
Running any non-trivial application on Kubernetes will most likely require authorized access to other components - databases, storage buckets, APIs - all of which require a connection string or some sort of access key. Storing these values in Kubernetes is done through Secrets, and while there are plenty of ways to make sure the secrets are safe while at rest, as well as how to configure an external KMS provider, once the secret is injected into your application container, its value will be plain text.
In this article we wil explore how to filter any Kubernetes secrets that end up in application logs - the entire project for this article can be found on GitHub, together with a sample application.
How to filter the logs of a Kubernetes pod
One approach could be to run a privileged DaemonSet that mounts the logs
directory and runs a filtering process on the logs. This presents the immediate
advantage of not having to modify your applications at all - however, filtering
the logs of all pods deployed on the cluster will be a highly intensive task,
and mounting part of the node filesystem inside a pod (that is privileged or
not) can prove to be disruptive. That is why, while this approach is mentioned
for completeness, is not recommended.
So, is there a way to filter the logs of a single application, in a non-privileged way? We can easily achieve this by making use of the sidecar pattern.
The sidecar pattern is a single node pattern made up of two containers. The first is the application container. It contains the core logic for the application. Without this container, the application would not exist. In addition to the application container, there is a sidecar container. The role of the sidecar is to augment and improve the application container, often without the application container’s knowledge. In its simplest form, a sidecar container can be used to add functionality to a container that might otherwise be difficult to improve.
Excerpt from the second chapter of the book Designing Distributed Systems, by Brendan Burns.
In a nutshell, this is our approach:
- forward the
stdoutof the main application container to a file - run a sidecar container and share the file where the main application container writes the logs
- run a filtering process in the sidecar that continuously reads the main
application log file and writes the filtered logs to the sidecar
stdout - collect the sidecar
stdoutas the application logs
Note that if you have an alpha cluster with shared PID namespaces - that is a cluster created with
--feature-gates=PodShareProcessNamespace=true, then you can access the main process’stdoutdirectly, without sharing a volume between the main container and the sidecar.
While this is still an alpha feature (thus not recommended for testing in production clusters), and we will continue to explore how to achieve this through volume mounts, this guide is still helpful, with the only difference that the logs file will be accessed in the sidecar as
/proc/<main-application-pid>/fd/1, which is the file descriptor ofstdout.
The main advantage of this approach is that we don’t need to mount parts of the
node filesystem in a pod, and we can enable the filter for individual
applications, filtering the secrets from a specific namespace. The only mention
here is that we should be able to redirect the logs of the main application to a
specific file. If that is not possible, explore running the sidecar by sharing
the PID namespace and accessing stdout directly.
The filtering process
The filtering application is a simple Go application that tails the file where
the main application writes the logs, iterates through all Kubernetes secrets in
the provided namespace, and checks if any value is present in the logs. If
found, it will remove it, then write the redacted log to stdout. This
container’s logs become the application logs:
func filter(line string, secrets []v1.Secret) string {
for _, s := range secrets {
for _, v := range s.Data {
// if the log line contains a secret value redact it
if strings.Contains(line, string(v)) {
line = strings.Replace(line, string(v), "[ redacted ]", -1)
}
}
}
return line
}
The filtering algorithm is fairly simple - it only does a strings.Contains on
the log line for every Kubernetes secret value in the namespace – this means
that the more secrets in the namespace, the more CPU cycles it will take to
filter a log – so be mindful of this when running in a namespace with lots of
secrets.
Note that the filtering function above is a simple example on how to process
your logs – for any production-purpose filtering, you should fork the
repository and replace the function with your own, and an immediate alternative
would be to use regex instead of the loop with strings.Contains – but you are
free to come up with virtually any filtering algorithm.
A Kubernetes cache is used in order to avoid getting all secrets from the API on every filtering request. The resync period for the cache is set to 30 seconds. If a new secret is added, then the application tries to print it before the cache resynced, that log will contain the secret value. If your use case demands it, reduce the resync period - but keep in mind the impact this will have on networking and on the API server.
Because of the simplicity of the filtering loop, any processing done to a secret
value (such as a base64 encoding), followed by printing it in the logs, will
not be caught by the current implementation – however, the filter can be
easily modified to accommodate additional transformations of values.
The filtering loop currently runs for for each new line. For a real world
scenario, filtering the logs in chunks of lines seems a reasonable approach –
this can be modified in the main function of the filter.
Important note: This method only prevents accidental printing of logs from an application output. It is not designed to prevent a potentially malicious attempt of gaining access to Kubernetes secrets – and it should be used accordingly.
The sample application
Now that we saw how the filtering process works, let’s see an example of this in action.
The sample, which is included in the GitHub repository, is a
simple NodeJS application that just logs the query parameters of every request.
The following section redirects the application stdout to a logs file whose
name is provided as an environment variable:
var logsFile = process.env.LOGS_FILE;
// redirect stdout and stderr to file
var access = fs.createWriteStream(logsFile);
process.stdout.write = process.stderr.write = access.write.bind(access);
This ensures all console.log calls from within the application will be
redirected to our desired logs file, which will be shared with the filtering
container through a volume mount.
Of course, the main application can be written in any language, and redirecting the logs to a file should be a fairly straightforward task in any modern framework.
Now we simply build a container image out of our application and push it to a container registry. Then, we need to create a Kubernetes manifest with the main application and the sidecar:
apiVersion: v1
kind: Pod
metadata:
name: filter-logs
spec:
# if running in a cluster without RBAC, remove the service account
serviceAccountName: filter-sa
containers:
- name: main-app
image: radumatei/node-redirect-stdout:alpine
env:
- name: LOGS_FILE
value: "/var/log/app"
volumeMounts:
- name: varlog
mountPath: /var/log
- name: filter
image: radumatei/filter-kubernetes-logs:latest
env:
- name: LOGS_FILE
value: "/var/log/app"
- name: NAMESPACE
value: "<your-namespace>"
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
This is a simple Kubernetes manifest for a pod with two containers: the main application container and the sidecar filter; we pass the logs file as environment variables to both containers, while also mounting a volume that contains the log file to both containers.
Please note that in the repo there is also a Kubernetes manifest that must be used on RBAC-enabled clusters – that is not shown here for brevity.
For simplicity, let’s create a new namespace:
$ kubectl create namespace filter-logs
Now in this namespace, create a new secret, according to the instructions in
the Kubernetes documentation. The values I used are:
super-secret-admin-username for the user name and
super-secret-admin-password for the password.
Now deploy the pod (and if needed, also the filter-role.yaml file containing
the RBAC objects). We expect that if the web application would
ever try to write super-secret-admin-username or super-secret-admin-password
(or the value of any secret in the namespace) in the logs, our filtering sidecar
would redact that.
Let’s see if that actually happens:
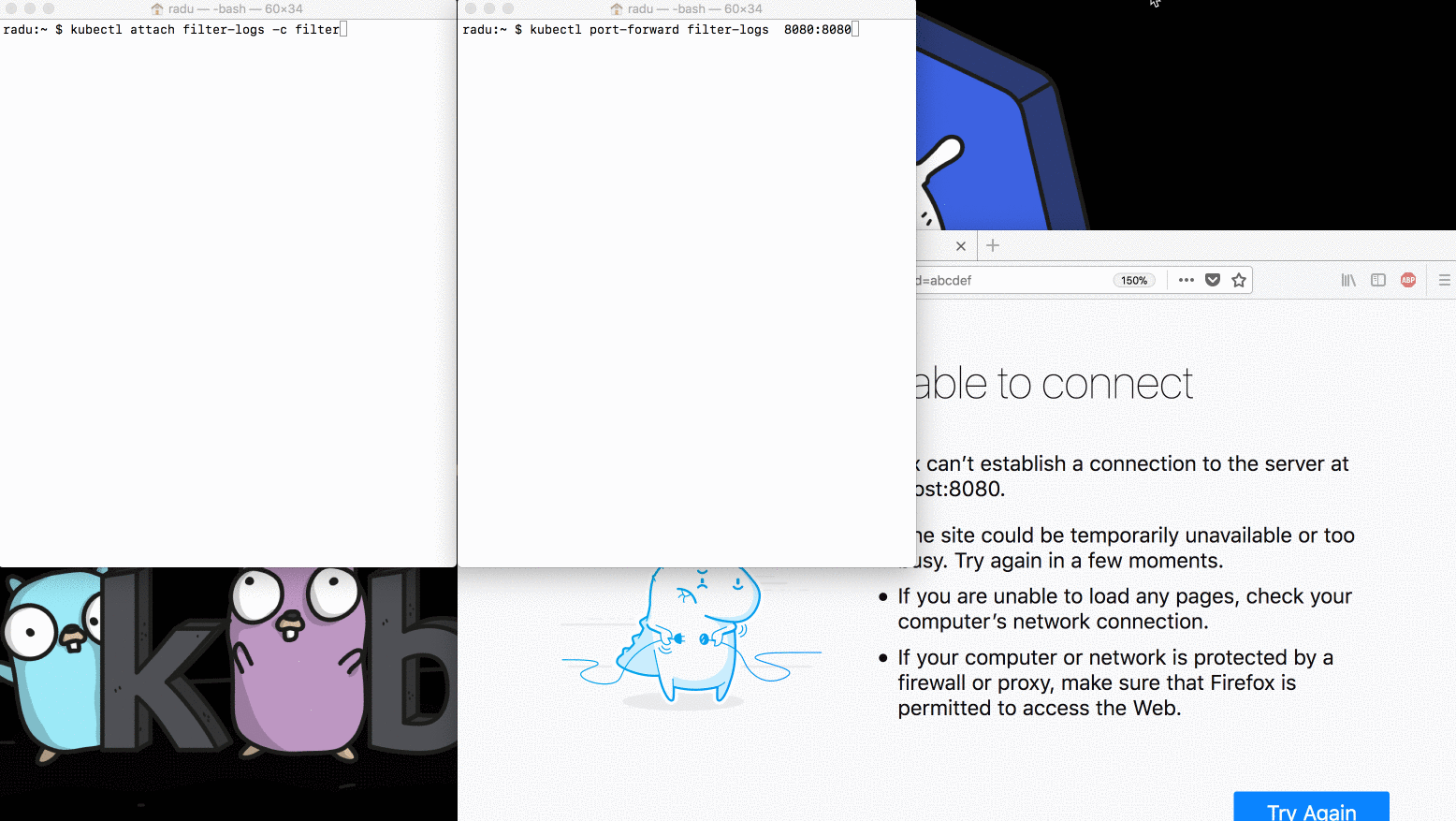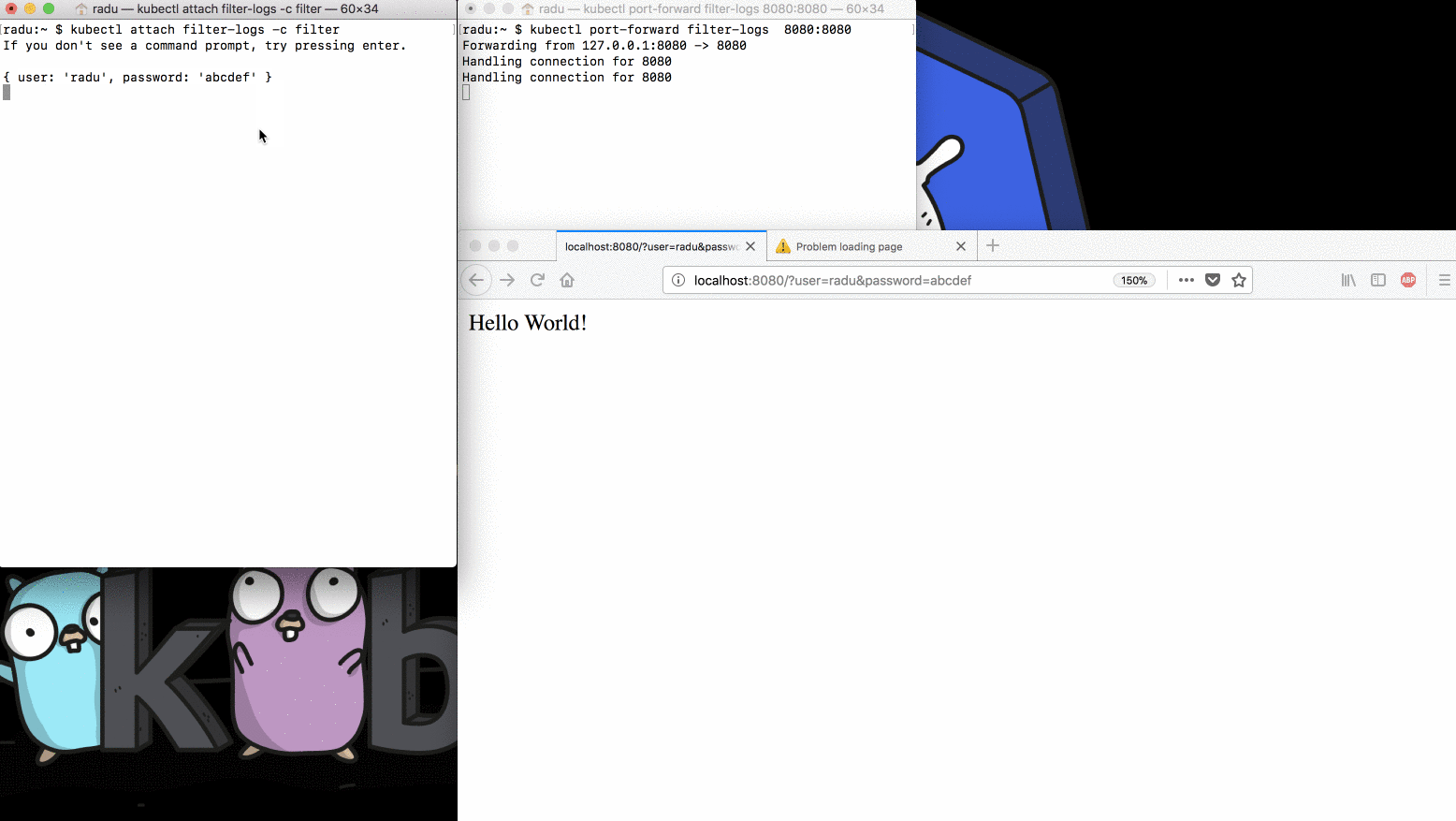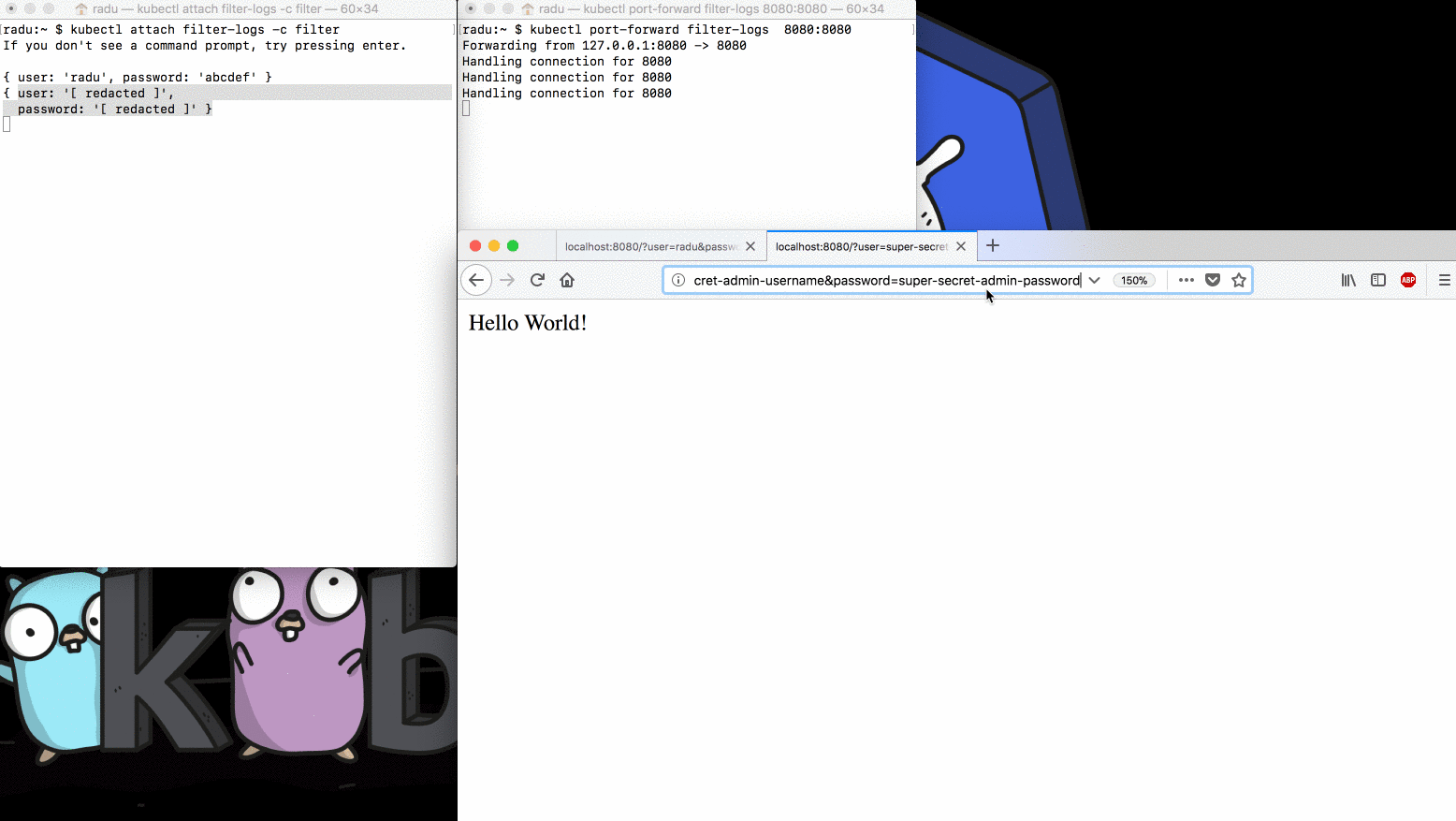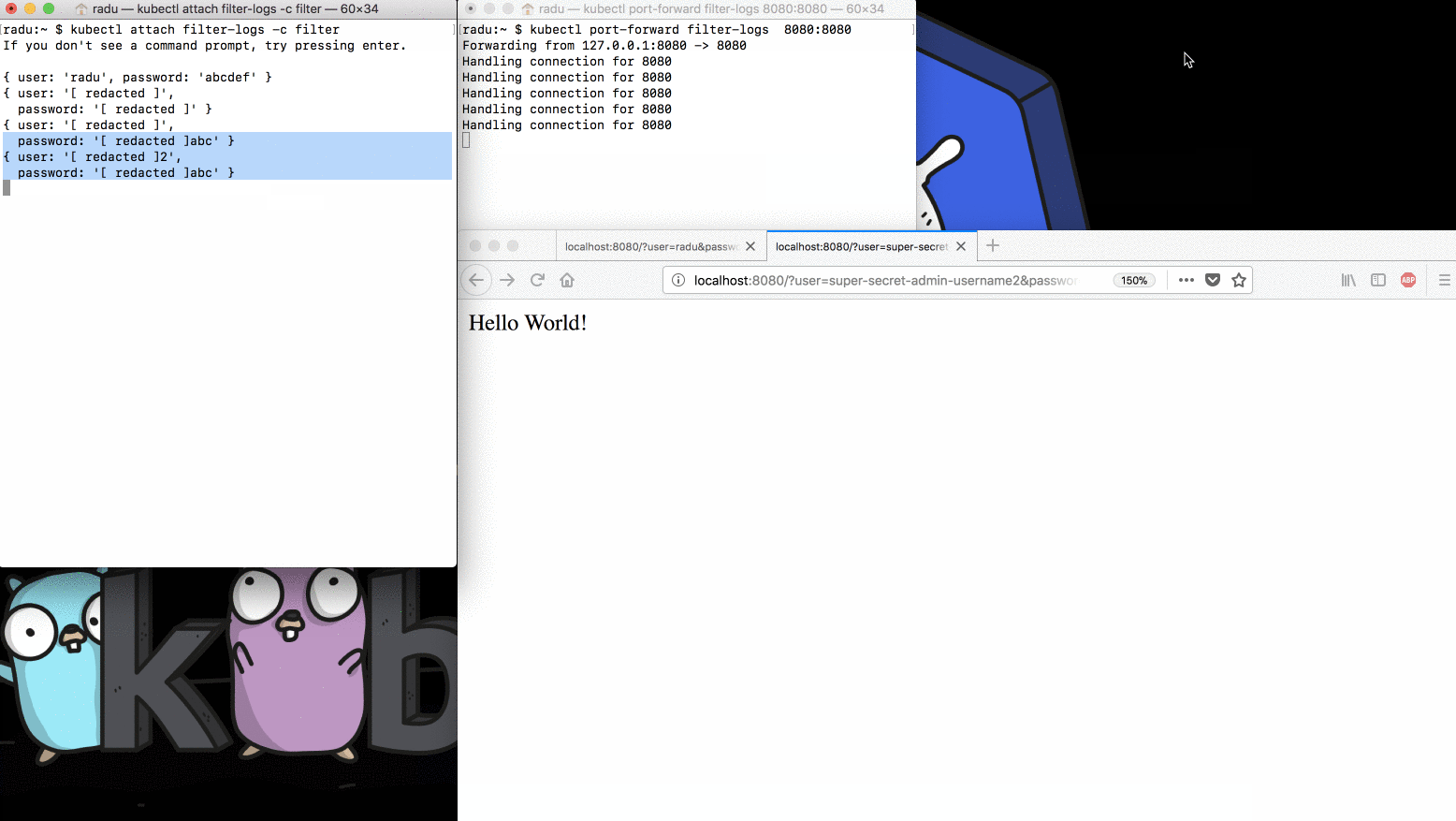
Clearly, the sidecar container redacts all secret values from the application
logs, so we avoid accidentally outputting secret values in the logs of our
applications. Executing kubectl logs also works as expected:
$ kubectl logs filter-logs -c filter
{ user: 'radu',
password: 'abcdef' }
{ user: '[ redacted ]',
password: '[ redacted ]' }
{ user: '[ redacted ]',
password: '[ redacted ]abc' }
{ user: '[ redacted ]2',
password: '[ redacted ]abc' }
Conclusion
In this article we saw how to filter Kubernetes secrets from the logs of our applications by running a sidecar container that continuously redacts the secret values from the logs. As mentioned, you are free to write your own filtering algorithm based on the needs of your application, as well as implement filtering in chunks of multiple log lines.
Thanks for reading, let me know your thoughts in the comments, and have fun filtering your application logs!